I installed back in 2013 when Greader died. Happened to come across the ttrss web page today and my ttrss doens’t look like screenshots. The upgrade screen of preferences claims I’m up to date. But how do I know that I actually am?
Thanks!
I installed back in 2013 when Greader died. Happened to come across the ttrss web page today and my ttrss doens’t look like screenshots. The upgrade screen of preferences claims I’m up to date. But how do I know that I actually am?
Thanks!
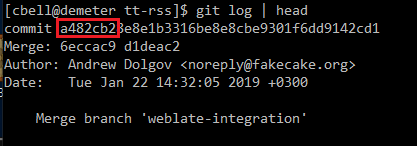
If you are in the top level directory in the command line, you can use “git log” and check the version:
If you’re in the web interface, go to Actions -> Preferences and look at the very bottom of the screen:
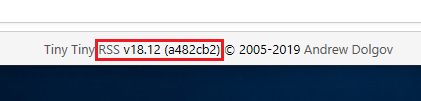
The 18.12 isn’t really meaningful. It’s the hexadecimal number that is most important (a482cb2). That reflects the actual latest commit you’re running.
Git doesn’t do anything - I get the error not a git repository.
And the bottom of my Preferences pages doesn’t have that. I do have a file in my directory called 1.7.5, though.
edit to add that everything in that folder has a date of March 22 2013 except the folder called feed-icons.
Well, the simple answer is…
No, you’re not up to date, you’re not anywhere close to being up to date.
Start here:
https://discourse.tt-rss.org/t/upgrading-to-use-git/540/2
If you’re confused read that whole thread then post back here in this one.
e: Please backup before doing anything. Database and a copy of your tt-rss directory.
Thanks @JustAMacUser. Had to add some stuff to the config file and had to convert my database from MYISAM to InnoDB. It’s currently updating the database schema. If that goes without errors/issues I should be OK. If not…I can reload the database and go to the old version, export OPML, and start from scratch.
Then, on a regular basis, do a ‘git pull’
Or just do it when this green icon with the exclamation mark shows up in the title bar…
I’m not sure that using your old database is a good idea. You mention needing to convert from MYISAM to InnoDB. I believe your database is already corrupted. MYISAM tables do not support “ON DELETE CASCADE” which Tiny Tiny RSS relies on to delete entries in multiple tables when an article or other object is deleted.
[cbell@demeter schema]$ grep "ON DELETE CASCADE" ttrss_schema_mysql.sql | wc -l
27
[cbell@demeter schema]$
You can see it’s used a lot in the database’s tables themselves. Every time a DELETE has been run against your database on one of the affected tables, cruft has been left behind elsewhere. It’s recommended (and I’m sure fox, SleeperService, et al. will agree) to start with a clean database.
I’ll have to leave it to others to address if using your old OPML is still safe.
Cruft is bad. bad bad bad.
Hey, you need to do an update ![]()
Nah - I dug around in the dev tools to remove the display:none; in the CSS to get that up ![]()
There’s a couple more in there:
![]()
you should export your OPML and start with a clean database, using postgres if you can
This is a fine note. Not only does it work like a charm, but it is the simplest way to upgrade.
it’s not normally needed but in this particular case, it is
i have no idea what exactly happens when converting myisam to innodb but i have severe doubts foreign key triggers and whatnot just magically appear and internal consistency of the database is somehow magically restored
this all has been said above though, i’m just reiterating the obvious
Oh yes, there’s been cruft building up for years. For example - All Articles: 424, but the tab in my browser shows the true number: 256. (and tha’ts been an issue for years, not just now when I converted to InnoDB)
Questions:
this is what happens when you explicitly ignore instructions (or think that you know better) and install on an unsupported database engine
The URLs and the settings (read in the Preferences → Feeds → OPML export), but this will not transfer the read status I would imagine.
You can also enable the “import_export” plugin to save stared and published articles (but I don’t know if this is the best idea with your crude tables?)
Just follow the instructions for basic installation and import afterwards. This means basically for you: create a new database.
It should work. It’s just collecting content, title, URL, etc. type info for each starred article then doing a proper insert of that article into the new database.
OK, thanks guys. Been going through it today and I’ve just got 64 unread articles left. I can probably finish that up over the next couple days and then do the OPML and leave it at that for the cleanest new experience possible.